
In this section, you will find recommendations on how to ensure FAIRness of DS and AI research artifacts during your project. Similar to the Before Research stage, try to first answer the questions presented in the figure below.
Note: Again, these questions apply to KGs/RKGs as well.
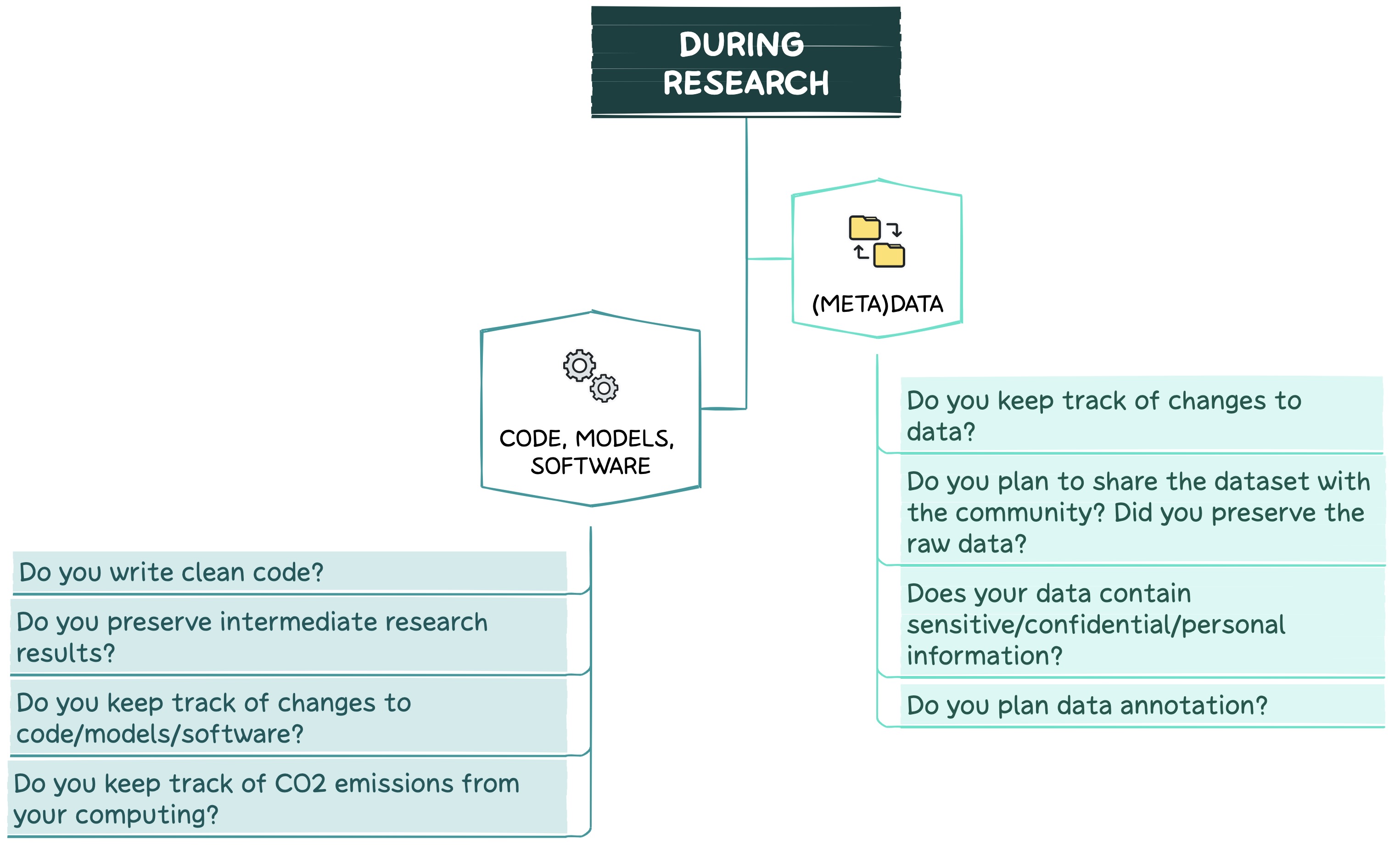
(Meta)data
- Don’t forget about Data Version Control and backups to keep track of changes and to avoid data loss.
- If the dataset is planned to be shared with the community, preserve a version of the raw data. This way other researchers will be able to preprocess and use it according to their study goals.
- In case of data with sensitive/confidential/personal information:
- Strong security measures must be taken to prevent data breaches and leakages. Some of the best practices for data protection are listed by RDMkit.
- Appropriate measures must be taken to protect the rights of data subjects (e.g., anonymisation, pseudonymisation, encryption, aggregation).
- If data annotation is planned:
- Decide on an annotation level, approach (manual/semi-automatic/automatic), and tool.
- Define the required input/output formats and their structure.
- Prepare tagsets/schemas and annotation guidelines. Those should be shared along with your research.
- Identify annotation efforts required (How many annotators? Experts vs crowdworkers?).
- Decide on which Inter Annotator Agreement (IAA) measure(s) to use in order to validate your annotation process.
For more details on documenting (meta)data, consult the following resources:
- Hugging Face Dataset Cards
- T. Gebru, J. Morgenstern, B. Vecchione, et al. Datasheets for Datasets. Communications of the ACM, vol. 64, no. 12, pp. 86–92, Dec. 2021. DOI: 10.1145/3458723.
Code, Models, and Software
- Follow clean code principles23, e.g., include unit tests.
- Don’t forget to save all your intermediate research results (e.g., evaluation scores along with model parameters) for future analysis.
- Use Version Control and external backups to keep track of changes and to avoid data loss.
- Constantly check energy consumption. For instance, you can use the CodeCarbon package which estimates the amount of carbon dioxide produced by computing resources and provides some tips on how to decrease emissions.
For more details on documenting code/models/software, consult the following resources:
- Hugging Face Model Cards
- M. Mitchell, S. Wu, A. Zaldivar, et al. Model Cards for Model Reporting. In Proceedings of the Conference on Fairness, Accountability, and Transparency. Association for Computing Machinery. 2019. DOI: 10.1145/3287560.3287596.
- The Machine Learning Reproducibility Checklist
tl;dr
(Meta)data:
Preserve various versions of your data (both raw and preprocessed) and back them up! If you are dealing with private/sensitive data, follow appropriate security and protection measures. If you are planning to annotate data, follow common practices for your specific annotation case.
Code, models, and software:
Write clean code and don’t forget about unit tests! Save your evaluation results and hyperparameters. Don’t forget about version control. Finally, check the energy consumption cost of running your code/models/software.